
2장
마이크로서비스 아키텍처를 구축할 때 프로젝트의 아키텍트는 다음 세 가지 일에 집중한다.
1. 비즈니스문제의 분해
2. 서비스 세분화의 확정
3. 서비스 인터페이스의 정의
1. 비즈니스 문제를 기술하고 그 문제를 기술하는 데 人居된 명사에 주목하라
문제를 기술하는 데 동일한 명사가 반복해서 사용되면 대개 핵심 비즈니스 영역과 마이크로서 비스로 만들 기회가 드러난다. 1장에서 EagleEye 영역의 대상 명사는 계약과 라이선스, 자산
같은 것이다. 2. 동사에주목하라
동사는 행위를 부각하고 문제가 되는 영역의 윤곽을 자연스럽게 드러낸다. 여러분이 “트랜잭 션 X 는 A와 B 에서 데 이 테 ■ 가져와야 해 .”라고 말한다면 대개 여러 서비스가 엮여 동작 중인 상태다. EagleEye에 동사 관찰 방법을 적용하면 “데스크톱 서비스 부서의 마이크(M ik)는 새 로운PC를설치할때소프트웨어X의라이선스개수를조회하고여분이있다면설치한다. 그 런 다음 장부에 라이선스 개수를 업데이트한다:’에서 핵심 동사는 조회하다(looks)와 업데이트하다 (updates) 이다.
3. 데이터응집성을찾아라
비즈니스 문제를 각 부분으로 분해할 때 서로 연관성이 높은 데이터 부분들을 찾는다. 마이크로 서비스는 자기 데이터를 완전히 소유해야 한다. 따라서 대화 중 갑자기 지금껏 논의했던 내용과 근본 적으로 다른 데이터를 읽거나 업데이트한다면 아마도 또 다른 서비스 후보가 필요할 수 있다.


No权 三 나쁜 마이크로서비스의 징후
마이크로서비스의 적절한 크기를 어떻게 알 수 있을까? 마이크로서비스가 너무 크게 나뉘어 있다면 다음 특징을 볼
수 있을 것이다.
• 책임이 너무 많은 서비스: 이 서비스에서 비즈니스 로직의 일반 흐름은 복잡하며 지나치게 다양한 종류의 비즈니스 규칙을 시행하게 된다.
• 많은 테이블의 데이터를 관리하는 서비스: 마이크로서비스는 자기가 관리하는 데이터를 기록하는 시스템이다. 여러 테이블에 데이터를 저장하거나 직속 데이터베이스 외부의 테이블에 액세스하고 있다면 서비스가 너무 크다는 것을 암시한다. 필자는 마이크로서비스가 3~5개 이내의 테이블을 소유해야 한다는 지침을 세웠다. 이보다 더 많다면 서 비스가 너무 많은 책임을 담당할 가능성이 높다.
• 과다한 테스트 케이스: 시간이 지나면서 서비스 크기와 책임이 늘어날 수 있다. 서비스가 적은 수의 테스트 케이스로 시작해 수백 개의 단위(unit) 테스트와 통IKintegration) 테스트 케이스로 늘어난다면 리팩토링이 필요할 것이다.
마이크로서비스가 너무 잘게 나뉘어 있다면 어떨까?
• 한 문제 영역 부분에 속한 마이크로서비스가 토끼처럼 번식한다: 모든 것이 마이크로서비스로 되면 작업 수행에 필 요한 서비스 개수가 엄청나게 증가해서 서비스에서 비즈니스 로직을 만드는 것이 복잡하고 어려워진다. 애플리케이 션에 수십 개의 마이크로서비스가 있고 각 서비스가 하나의 데이터베이스 테이블과 통신할 때 악취가 나곤 한다.
• 마이크로서비스가 지나치게 상호 의존적이다: 문제 영역의 한 부분에 있는 마이크로서비스는 하나의 사용자 요청을 완료하기 위해 각 서비스가 서로 계속 호출한다.
• 마이크로서비스가 단순한 CRUD(Create, Read, Update, Delete) 집합이 된다: 마이크로서비스는 비즈니스 로직의 표현이지 데이터 소스(data sources)의 추상화 계층이 아니다. 마이크로서비스가 CRUD 관련 로직만 수 행한다면 너무 잘게 나뉘어 있다는 의미다.
2.1.3 서비스 사이의 대화: 서비스 인터페이스
아키텍트가 제공할 마지막 부분은 애플리케이션의 마이크로서비스가 대화하는 방식을 정의하는 것이다. 마이크로서비스를 사용해 비즈니스 로직을 만든다면 서비스 인터페이스는 직관적이고, 개발자가 1〜 2 개의 애플리케이션 서비스를 학습하고 나면 애플리케이션의 모든 서비스에 대한 동 작 규칙을 습득할 수 있어야 한다.
일반적으로 서비스 인터페이스 설계를 고려할 때 다음 지침을 入]용할 수 있다.
1. REST철학을수용하라:서비스에대한REST 방식은서비스의호출프로토콜로 HTTP를수용 하고표준HTTP 동사(GET, PUT, POST, DELETE)를사용하는것이핵심이다. HTTP 동 사를 기반으로 기본 행동 양식을 모델링한다.
2. URI를 사용해 의도(imem)를 전달하라: 서비스의 엔드포인트로 사용되는 URI는 문제 영역에 존재 하는 다양한 자원을 기술하고 자원 관계에 대한 기본 메커니즘을 제공해야 한다.
3. 요청(reque«)과응답(response)에JSON을사용하라:JSON은초경량데이터직렬화프로토콜이며 X M L 보다 훨씬 시용하기 쉽다.
U. HTTP 상태 코드로 결과를 전달하라: HTTP 프로토콜에는 서비스의 성공과 실패를 명시하는 풍 부한표준응답코드가있다. 상태코드를익히고모든서비스에 일관되게사용하는것이매우 중요하다.
2 -2 마이크로서비스를a]용하지않아이:할때
이 장에서 마이크로서비스가 애플리케이션을 구축할 수 있는 강력한 아키텍처 패턴인 이유를 설명 했지만, 언제 마이크로서비스를 사용하면 안 되는지는 다루지 않았다. 차례대로 하나씩 살펴보자.
1. 분산시스템구축의 복잡성
2 . 가상 서버/컨테이너의 스프롤(sprawl)1
3 . 애플리케이션유형
U. 데이터 변환과 일관성
2.2.1 분산 시스템 구축의복잡성
마이크로서비스는 잘게 나뉘고 분산되어 있어 모놀리식 애플리케이션에서 없던 복잡성을 가져온
다. 마이크로서비스 아키텍처에는 높은 수준의 운영 성숙도도 필요하다. 따라서 T1 도로■분산된 애
플리케이션을 성공시키는 데 필요한 자동화와 운영 작업(모니터링과 확장)에 투자할 의사가 없는 조직이라면 마이크로서 비스를 고려하지 않는 것이 좋다.
2.2.2 서버 스프롤(server sprawl)
마이크로서비스의 가장 일반적인 배포 모델 중 하나는 한 서버에 하나의 마이크로서비스 인스턴 스를 배포하는 것이다. 대규모 마이크로서비스 기반 애플리케이션의 운영 환경에서만 구축 및 관 리가 필요한 서버나 컨테이너가(일반적으로 가상의) 50〜 100개 있을 수 있다. 클라우드에서 이들 서비스를 실행하는 데 드는 비용은 저렴하더라도 서버를 관리하고 모니터링하는 운영 작업은 엄 청나게 복잡해질 수 있다.
2.2.3 애플리케이션유형
마이크로서비스는 재사용성을 추구하며 높은 회복성과 확장성이 필요한 대규모 애플리케이션의
구축에 매우 유용하다. 이 때문에 많은 클라우드 기반 기업에서 마이크로서비스를 채택한다. 부서 수준의 소형 애플리케이션이나 소수 사용자를 위한 애플리케이션을 개발할 때 마이크로서비스와
같은 분산 모델로 구축한다면 구축에 따른 복잡성이 얻게 될 가치보다 더 클 수 있다.
22M 데이터변환과일관성
마이크로서비스를 검토할 때 여러분은 서비스의 데이터 사용 패턴과 서비스 소비자가 어떻게 서 비스를 사용하는지 고민해야 한다. 마이크로서비스는 적은 수의 테이블을 둘러싸고 추상화하며, 저장소에 단순한(복합적이지 않은) 질의 생성, 추가, 실행 등 ‘운영상의’ 작업을 수행하는 메커니즘 으로도 잘 동작한다.
애플리케이션이 여러 데이터 소스에서 복잡한 데이터를 취합하고 변환해야 할 경우 마이크로서비 스의 분산된 특성 때문에 작업이 어려워진다. 마이크로서비스는 변함없이 과도한 책임을 떠안고 성능 문제에도 취약해질 것이다.
마이크로서비스 사이에 트랜잭션을 처리하는 표준이 없다는 사실도 잊지 말자. 트랜잭션 관리가 필요하다면 직접 만들어야 한다. 7 장에서 살펴보겠지만 마이크로서비스는 메시지를 사용해 서로
통신할 수 있다. 메시징에서는 데이터를 업데이트할 때 지연 시간(ktemy)이 발생한다. 따라서 업 데이트한 데이터가 즉시 나타나지 않을 수도 있어 애플리케이션은 최종 일관성(weiitual consistency)
을 유지해야 한다.
2.4 데브옵스 이야기: 혹독한 론타임 구축
서비스 어셈블리(service assembly):동일한 서비스 코드와 런타임을 정확히 같은 방식으로 배포하 기 위해 반복성과 일관성을 보장하는 서비스 패키징과 배포 방식은 무엇인가?
• 서비스 부트스트래핑(service bootstrapping) :사람이 개입하지 않아도 모든 환경에 마이크로서비스 인스턴스를 신속하게 시작하고 배포하기 위해 애플리케이션과 환경별 구성 코드를 런타임 코드와 분리하는 방법은 무엇인가?
• 서비스 등록 및 디스커버리(service registration/discovery): 새로운 마이크로서비스 인스턴스가 배포 될 때 다른 애플리케이션 클라이언트가 발견할 수 있게 만드는 방법은 무엇인가?
• 서비스 모니터링(service monitoring): 마이크로서비스 환경에서 매우 높은 가용성을 요구하기 때
문에 동일 서비스를 여러 인스턴스로 실행히는 것은 일반적이다. 데브옵스 관점에서 마이크 로서비스 인스턴스를 모니터링하고 마이크로서비스 고장을 회피하는 라우텅과 비정상 서비 스 인스턴스를 제거하•지 확인해야 한다.

2.4.1 서비스어셈블리:마이크로서비스의패키징과배포
마이크로서비스 아키텍처의 핵심 개념 중 하나는 애플리케이션의 환경 변화(예를 들어 갑작스런 사용자 요청이 유입되거나 인프라스트럭처의 문제가 발생하는 등) 어1 대
응해 마이크로서비스의 여러 인스턴스를 신속하게 배포할수 있다는 것이다.

mvn clean package && java -jar target/licensing-service-0.0.1-SNAPSHOT.jar
2.4.2 서비스부트스트래핑:마이크로서비스의구성관리
마이크로서비스가 처음 가 동할 때 시작하며 애플리케이션 구성 정보를 로드(load)한다

2.4.3 서비스등록과디스커버리:클라이언트가마이크로서비스와 통신하는 방법
마이크로서비스 소비자 관점에서 마이크로서비스는 위치 투명성을 가져야 한다. 클라우드 기반 환경에서 서버는 일시적(ephemerd)이기 때문이다. ‘일시적’이라는 말은 서비스를 호스팅하는 서버 수명이 기업 데이터센터에서 실행되는 서비스보다 더 짧다는 것을 의미한다. 클라우드 기반 서비 스는 실행될 서버에 완전히 새로운 IP 주소를 할당받고 신속히 시작하고 제거될 수 있다.
모든 서비스에는 고유하고 비영구적인 IP 주소가 할당된다. ‘ 일시적’ 서비스의 단점은 끊임없이 서비스의 시작과 종료를 반복하는 상황에 서 일시적 서비스를 대량으로 수동 또는 직접 관리하면서 장애가 발생할 수 있다는 것이다.
마이크로서비스 인스턴스는 제3 자 에이전트에 스스로 등록해야 하는데 이 등록 과정을 서비스 디 스커버리(service discovery)라고 한다(그림 2 - 6 의 세 번째 단계다). 마이크로서비스 인스턴스를 서비 스 디스커버리 에이전트에 등록할 때 인스턴스의 물리적인 IP 주소 또는 도메인 주소와 애플리케 이션이 서비스 검색에 사용할 논리적인 서비스 이름, 이 두 가지 정보를 에이전트에 전달한다. 어 떤 서비스 디스커버리 에이전트는 상태 확인(ht'akh check)을 하는 데 필요한 URL을 등록하려는 서 비스에 요구하기도 한다.
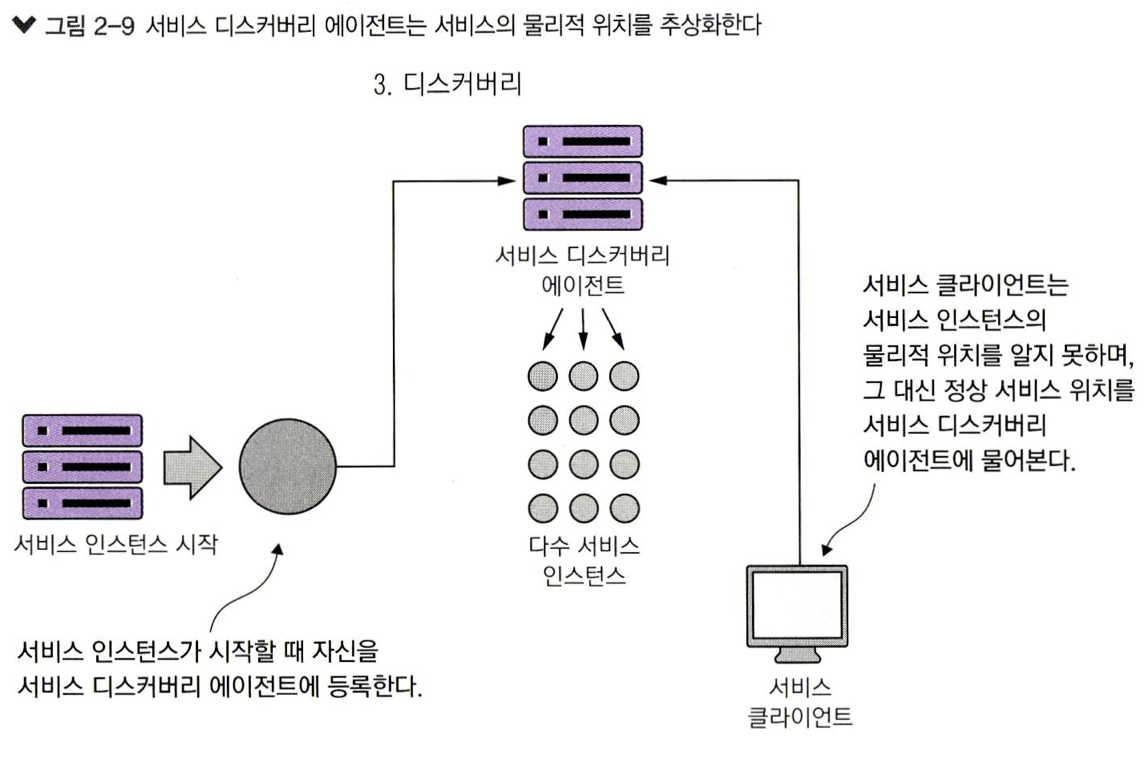
2.4.4 마이크로서비스의 상태 전달
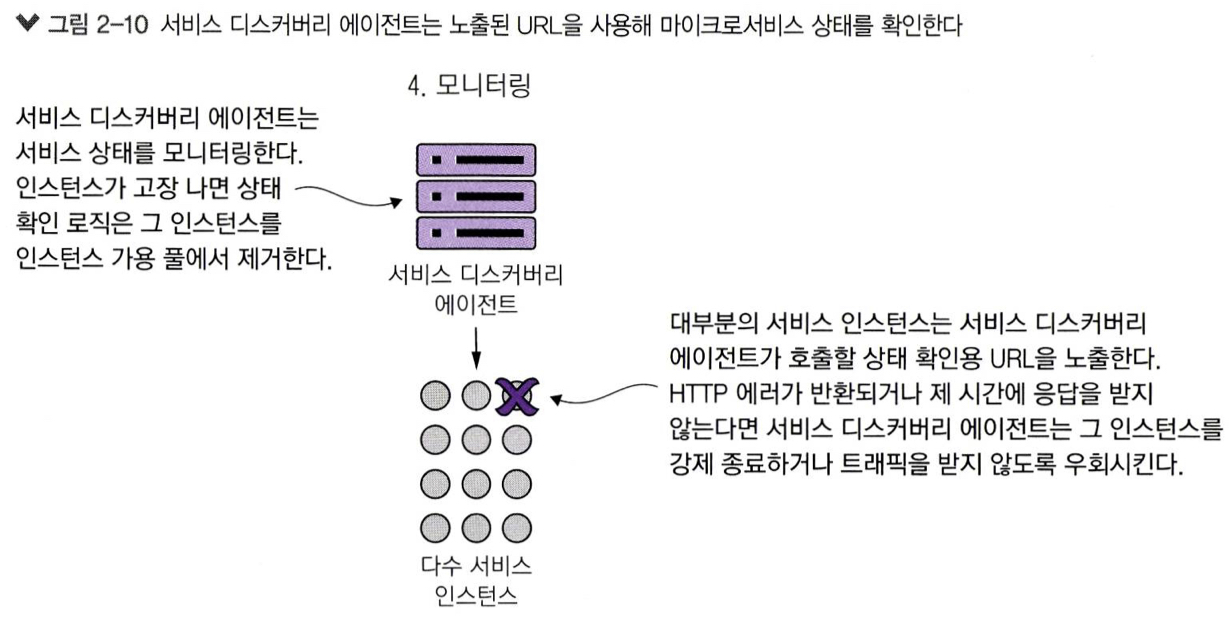
서비스 디스커버리 에이전트는 클라이언트에 서비스 위치를 안내하는 교통 경찰 역할만 하는 것 은 아니다. 클라우드 기반 마이크로서비스 애플리케이션에서는 종종 어떤 서비스의 많은 인스턴 스가실행될수있고언젠가그서비스인스턴스중하나가고장날것이다. 서비스디스커버리에 이전트는 등록된 각 서비스 상태를 모니터링한다. 그리고 클라이언트가 고장 난 서비스를 호출하 지 않도록 자신의 라우팅 테이블에서 문제가 된 서비스 인스턴스를 제거한다.
마이크로서비스가 실행되면 서비스 디스커버리 에이전트는 해당 서비스가 가용한지 확인하기 위 해 상태 확인 인터페이스(health check interface)를 계속 모니터링하고 핑(ping)한다. 그림 2 - 6 의 네 번 째 단계로 그림 2 - 1 0 에서 자세히 보여 준다.
일관된 상태 확인 인터페이스를 구축하면 여러 클라우드 기반 모니터링 도구를 시용해 문제를 감 지하고 적절히 대응할수 있다.
서비스 디스커버리 에이전트가 어떤 서비스 인스턴스에 문제를 발견하면 망가진 인스턴스를 정지 시키거나 새로운 서비스를 추가하는 등 조치를 취할 수 있다.
REST 기반마이크로서비스환경에서상태확인인터페이스를만드는가장단순한방법은JSON 페이로드와HTTP 상태코드를반환하는HTTP 엔드포인트를노출하는것이다. 스프링부트가 사용되지 않는 마이크로서비스에서 서비스 상태를 제공할 엔드포인트를 작성하는 일은 대개 개발 자 몫이다.
2.6 요약
• 마이크로서비스는 강력한 아키텍처 패러다임이지만 혜택과 장단점이 있다. 모든 애플리케 이션이 마이크로서비스 애플리케이션일 필요는 없다.
• 아키텍트 관점에서 마이크로서비스는 작고, 자체 완비형이며 분산된 것이다. 마이크로서비 스는 좁은 범위와 소규모 데이터를 관리한다.
• 개발자관점에서REST 설계방식과서비스의데이터송수신을위한JSON을사용해마이 크로서비스를 구축한다.
• 데브옵스 관점에서 마이크로서비스를 패키징, 배포,모니터링하는 방법은 매우 중요하다.
• 스프링부트를사용하면서비스를하나의JAR 실행파일로전달할수있다.JAR 파일에내
장된 톰켓 서버가 서비스를 호스팅한다.
• 스프링 부트 프레임워크에 포함된 스프링 액추에이터는 서비스 런타임 정보와 함께 서비스
의 운영 상태 정보도 제공한다.
Note. Twelve-Factor 마이크로서비스 서비스 애플리케이션 구축
이 책을 향한 필자의 큰 바람 중 하나는 여러분이 성공적인 마이크로서비스 아키텍처를 위해 강력한 애플리케이션 개 발과 데브옵스 실천(practice)이 필요함을 깨닫는 것이다. 이러한 실천의 간결한 요약 중 하나가 허로쿠의 Twelveᅳ Factor 애플리케이션 선언(Heroku’s Twelve-Factor Application manifesto, https://12factor.net/)이다. 이 문서는 항상 기억해야 할 12개의 모범 지침을 제공한다. 책을 읽으면서 이러한 실천 사항이 예제에 녹아 있는 것을 알 수 있다.
• 코드베이스(codebase): 모든 애플리케이션 코드와 서버 프로비저닝(provisioning) 정보는 버전 관리(version control)되어야 한다. 각 口ᅡ이크로서비스는 소스 제어 시스템 안에 독립적인 코드 저장소를 가져야 한다.
• 의존성(dependencies): 애플리케이션이 사용하는 의존성을 메이븐(자바) 같은 빌드 도구를 이용해 명시적으로 선언해야 한다. 제3자(3rd party)의 JAR 의존성은 특정 버전 번호를 붙여 명시해 선언해야 한다. 따라서 동일 버전 의 라이브러리를 人f용해 항상 마이크로서비스를 빌드할 수 있다.
• 구성(config): 애플리케이션 구성(특히 환경별 구성)을 코드와 독립적으로 저장하자. 애플리케이션 구성은 절대로 소스 코드와 동일한 저장소에 있으면 안 된다.
• 백엔드 서비스(backing services):마이크로서비스는 대개 네트워크를 거쳐 데이터베이스나 메시징 서비스와 통 신한다. 그렇다면 언제든 데이터베이스 구현을 자체 관리형 서비스에서 외부업체 서비스로 교체할 수 있어야 한다. 10장에서 로컬에서 관리되는 Postgres 데이터베이스를 AWS 데이터베이스로 옮기면서 이를 보여 준다.
• 빌드,릴리스,실행(build, release, run):배포할 애플리케이션의 빌드, 릴리스, 실행 부분을 철저히 분리하라. 코 드가 빌드되면 개발자는 실행 중에 코드를 변경할 수 없다. 모든 변경 사항을 빌드 프로세스로 되돌려 재배포해야 한다. 빌드된 서비스는 불변적이므로(immutable) 변경할 수 없다.
• 프로세스(processes): 마이크로서비스는 항상 무상태(stateless) 방식을 사용해야 한다. 서비스 인스턴스 손실에 의해 데이터가 손실될 것이라는 우려 없이 언제든 서비스를 강제 종료하거나 교체할 수 있다.
• 포트 바인딩(port binding):마이크로서비스는 서비스용 런타임 엔진을 포함한(실행 파일에 패키징된 서비스를 포 함한) 완전히 자체 완비형이다. 별도의 웹 또는 애플리케이션 서버 없이도 서비스는 실행되어야 한다. 서비스는 명 령행에서 단독으로 시작하고 노출한 HTTP 포트를 통해 즉시 액세스할 수 있어야 한다.
• 동시성(concurrency): 확장해야 한다면 단일 서비스 안에서 스레드 모델에 의존하지 마라. 그 대신 더 많은 마이 크로서비스를 시작하고 수평 확장하라. 마이크로서비스 안에서 스레드 人I용을 배제하지는 않지만 확장을 위한 유일 한 메커니즘으로 믿지 말라. 수직 대신 수평 확장하라.
• 폐기 가능(disposability): 마이크로서비스는 폐기 가능하므로 요구에 따라 시작 및 중지할 수 있다. 시작 시간은 최소화하고 운영 체제에서 강제 종료 신호(kill signal雇 받으면 프로세스는 적절히 종료(gracefully shut down) 해야 한다.
• 개발 및 운영 환경 일치(dev/prod parity):서비스가 실행되는 모든 환경(개발자의 데스크톱 환경도 포함) 人삐의 차이를 최소화하라. 개발자는 서비스 개발을 위해 실제 서비스가 실행되는 동일한 인프라스트럭처를 로컬에 사용해 야 한다. 이는 환경 간 서비스 배포가 수 주가 아닌 수 시간 안에 이루어져야 한다는 것을 의미한다. 코드가 커밋되 자마자 테스트되고 가능한 신속하게 개발 환경에서 운영 환경으로 전파되어야 한다.
• 로그(logs): 로그는 이벤트 스트림이다. 로그가 기록될 때 스플렁크(Splunk, http://splunk.com)나 Fluentd (http://fluentd.org) 같은 도구로 로그가 스트리밍되어야 한다. 이들 도구는 로그를 수집해 중앙에 기록한다. 마이 크로서비스는 이러한 로깅 동작 방식에 신경 쓰지 않아야 하며, 개발자는 표준 출력(stdout)으로 출력된 로그를 시 각적으로 확인할 수 있어야 한다.
• 관리 프로세스(Admin processes):개발자는 종종 담당 서비스에 대해 데이터 마이그레이션이나 변환처럼 관리 작업을 수행해야 한다. 이러한 작업은 임의로 수행되면 안 되고 소스 코드 저장소에 유지 및 관리되는 스크립트에 의해 수행되어야 한다. 이 스크립트는 실행될 각 환경에 반복적으로 수행 가능하고 환경을 위해 변경되지 않아야 한 다. 즉, 각 환경에 맞추어 스크립트를 수정하지 않는다.
'프로그래밍 > 스프링' 카테고리의 다른 글
| [스프링 인 액션] 3. JDBC와 JPA (0) | 2024.03.02 |
|---|---|
| [스프링 인 액션] 0. 이 책을 다시 읽는 이유 (0) | 2024.02.27 |
| [스프링 마이크로서비스 코딩 공작소] 1. 스프링, 클라우드와 만나다 (3) | 2023.08.21 |
| [스프링 마이크로서비스 코딩 공작소] 0. 개요 (0) | 2023.08.20 |
| 2. 서블릿 - 1)서블릿 생명주기, 초기화 (0) | 2018.11.18 |
2장
마이크로서비스 아키텍처를 구축할 때 프로젝트의 아키텍트는 다음 세 가지 일에 집중한다.
1. 비즈니스문제의 분해
2. 서비스 세분화의 확정
3. 서비스 인터페이스의 정의
1. 비즈니스 문제를 기술하고 그 문제를 기술하는 데 人居된 명사에 주목하라
문제를 기술하는 데 동일한 명사가 반복해서 사용되면 대개 핵심 비즈니스 영역과 마이크로서 비스로 만들 기회가 드러난다. 1장에서 EagleEye 영역의 대상 명사는 계약과 라이선스, 자산
같은 것이다. 2. 동사에주목하라
동사는 행위를 부각하고 문제가 되는 영역의 윤곽을 자연스럽게 드러낸다. 여러분이 “트랜잭 션 X 는 A와 B 에서 데 이 테 ■ 가져와야 해 .”라고 말한다면 대개 여러 서비스가 엮여 동작 중인 상태다. EagleEye에 동사 관찰 방법을 적용하면 “데스크톱 서비스 부서의 마이크(M ik)는 새 로운PC를설치할때소프트웨어X의라이선스개수를조회하고여분이있다면설치한다. 그 런 다음 장부에 라이선스 개수를 업데이트한다:’에서 핵심 동사는 조회하다(looks)와 업데이트하다 (updates) 이다.
3. 데이터응집성을찾아라
비즈니스 문제를 각 부분으로 분해할 때 서로 연관성이 높은 데이터 부분들을 찾는다. 마이크로 서비스는 자기 데이터를 완전히 소유해야 한다. 따라서 대화 중 갑자기 지금껏 논의했던 내용과 근본 적으로 다른 데이터를 읽거나 업데이트한다면 아마도 또 다른 서비스 후보가 필요할 수 있다.
No权 三 나쁜 마이크로서비스의 징후
마이크로서비스의 적절한 크기를 어떻게 알 수 있을까? 마이크로서비스가 너무 크게 나뉘어 있다면 다음 특징을 볼
수 있을 것이다.
• 책임이 너무 많은 서비스: 이 서비스에서 비즈니스 로직의 일반 흐름은 복잡하며 지나치게 다양한 종류의 비즈니스 규칙을 시행하게 된다.
• 많은 테이블의 데이터를 관리하는 서비스: 마이크로서비스는 자기가 관리하는 데이터를 기록하는 시스템이다. 여러 테이블에 데이터를 저장하거나 직속 데이터베이스 외부의 테이블에 액세스하고 있다면 서비스가 너무 크다는 것을 암시한다. 필자는 마이크로서비스가 3~5개 이내의 테이블을 소유해야 한다는 지침을 세웠다. 이보다 더 많다면 서 비스가 너무 많은 책임을 담당할 가능성이 높다.
• 과다한 테스트 케이스: 시간이 지나면서 서비스 크기와 책임이 늘어날 수 있다. 서비스가 적은 수의 테스트 케이스로 시작해 수백 개의 단위(unit) 테스트와 통IKintegration) 테스트 케이스로 늘어난다면 리팩토링이 필요할 것이다.
마이크로서비스가 너무 잘게 나뉘어 있다면 어떨까?
• 한 문제 영역 부분에 속한 마이크로서비스가 토끼처럼 번식한다: 모든 것이 마이크로서비스로 되면 작업 수행에 필 요한 서비스 개수가 엄청나게 증가해서 서비스에서 비즈니스 로직을 만드는 것이 복잡하고 어려워진다. 애플리케이 션에 수십 개의 마이크로서비스가 있고 각 서비스가 하나의 데이터베이스 테이블과 통신할 때 악취가 나곤 한다.
• 마이크로서비스가 지나치게 상호 의존적이다: 문제 영역의 한 부분에 있는 마이크로서비스는 하나의 사용자 요청을 완료하기 위해 각 서비스가 서로 계속 호출한다.
• 마이크로서비스가 단순한 CRUD(Create, Read, Update, Delete) 집합이 된다: 마이크로서비스는 비즈니스 로직의 표현이지 데이터 소스(data sources)의 추상화 계층이 아니다. 마이크로서비스가 CRUD 관련 로직만 수 행한다면 너무 잘게 나뉘어 있다는 의미다.
2.1.3 서비스 사이의 대화: 서비스 인터페이스
아키텍트가 제공할 마지막 부분은 애플리케이션의 마이크로서비스가 대화하는 방식을 정의하는 것이다. 마이크로서비스를 사용해 비즈니스 로직을 만든다면 서비스 인터페이스는 직관적이고, 개발자가 1〜 2 개의 애플리케이션 서비스를 학습하고 나면 애플리케이션의 모든 서비스에 대한 동 작 규칙을 습득할 수 있어야 한다.
일반적으로 서비스 인터페이스 설계를 고려할 때 다음 지침을 入]용할 수 있다.
1. REST철학을수용하라:서비스에대한REST 방식은서비스의호출프로토콜로 HTTP를수용 하고표준HTTP 동사(GET, PUT, POST, DELETE)를사용하는것이핵심이다. HTTP 동 사를 기반으로 기본 행동 양식을 모델링한다.
2. URI를 사용해 의도(imem)를 전달하라: 서비스의 엔드포인트로 사용되는 URI는 문제 영역에 존재 하는 다양한 자원을 기술하고 자원 관계에 대한 기본 메커니즘을 제공해야 한다.
3. 요청(reque«)과응답(response)에JSON을사용하라:JSON은초경량데이터직렬화프로토콜이며 X M L 보다 훨씬 시용하기 쉽다.
U. HTTP 상태 코드로 결과를 전달하라: HTTP 프로토콜에는 서비스의 성공과 실패를 명시하는 풍 부한표준응답코드가있다. 상태코드를익히고모든서비스에 일관되게사용하는것이매우 중요하다.
2 -2 마이크로서비스를a]용하지않아이:할때
이 장에서 마이크로서비스가 애플리케이션을 구축할 수 있는 강력한 아키텍처 패턴인 이유를 설명 했지만, 언제 마이크로서비스를 사용하면 안 되는지는 다루지 않았다. 차례대로 하나씩 살펴보자.
1. 분산시스템구축의 복잡성
2 . 가상 서버/컨테이너의 스프롤(sprawl)1
3 . 애플리케이션유형
U. 데이터 변환과 일관성
2.2.1 분산 시스템 구축의복잡성
마이크로서비스는 잘게 나뉘고 분산되어 있어 모놀리식 애플리케이션에서 없던 복잡성을 가져온
다. 마이크로서비스 아키텍처에는 높은 수준의 운영 성숙도도 필요하다. 따라서 T1 도로■분산된 애
플리케이션을 성공시키는 데 필요한 자동화와 운영 작업(모니터링과 확장)에 투자할 의사가 없는 조직이라면 마이크로서 비스를 고려하지 않는 것이 좋다.
2.2.2 서버 스프롤(server sprawl)
마이크로서비스의 가장 일반적인 배포 모델 중 하나는 한 서버에 하나의 마이크로서비스 인스턴 스를 배포하는 것이다. 대규모 마이크로서비스 기반 애플리케이션의 운영 환경에서만 구축 및 관 리가 필요한 서버나 컨테이너가(일반적으로 가상의) 50〜 100개 있을 수 있다. 클라우드에서 이들 서비스를 실행하는 데 드는 비용은 저렴하더라도 서버를 관리하고 모니터링하는 운영 작업은 엄 청나게 복잡해질 수 있다.
2.2.3 애플리케이션유형
마이크로서비스는 재사용성을 추구하며 높은 회복성과 확장성이 필요한 대규모 애플리케이션의
구축에 매우 유용하다. 이 때문에 많은 클라우드 기반 기업에서 마이크로서비스를 채택한다. 부서 수준의 소형 애플리케이션이나 소수 사용자를 위한 애플리케이션을 개발할 때 마이크로서비스와
같은 분산 모델로 구축한다면 구축에 따른 복잡성이 얻게 될 가치보다 더 클 수 있다.
22M 데이터변환과일관성
마이크로서비스를 검토할 때 여러분은 서비스의 데이터 사용 패턴과 서비스 소비자가 어떻게 서 비스를 사용하는지 고민해야 한다. 마이크로서비스는 적은 수의 테이블을 둘러싸고 추상화하며, 저장소에 단순한(복합적이지 않은) 질의 생성, 추가, 실행 등 ‘운영상의’ 작업을 수행하는 메커니즘 으로도 잘 동작한다.
애플리케이션이 여러 데이터 소스에서 복잡한 데이터를 취합하고 변환해야 할 경우 마이크로서비 스의 분산된 특성 때문에 작업이 어려워진다. 마이크로서비스는 변함없이 과도한 책임을 떠안고 성능 문제에도 취약해질 것이다.
마이크로서비스 사이에 트랜잭션을 처리하는 표준이 없다는 사실도 잊지 말자. 트랜잭션 관리가 필요하다면 직접 만들어야 한다. 7 장에서 살펴보겠지만 마이크로서비스는 메시지를 사용해 서로
통신할 수 있다. 메시징에서는 데이터를 업데이트할 때 지연 시간(ktemy)이 발생한다. 따라서 업 데이트한 데이터가 즉시 나타나지 않을 수도 있어 애플리케이션은 최종 일관성(weiitual consistency)
을 유지해야 한다.
2.4 데브옵스 이야기: 혹독한 론타임 구축
서비스 어셈블리(service assembly):동일한 서비스 코드와 런타임을 정확히 같은 방식으로 배포하 기 위해 반복성과 일관성을 보장하는 서비스 패키징과 배포 방식은 무엇인가?
• 서비스 부트스트래핑(service bootstrapping) :사람이 개입하지 않아도 모든 환경에 마이크로서비스 인스턴스를 신속하게 시작하고 배포하기 위해 애플리케이션과 환경별 구성 코드를 런타임 코드와 분리하는 방법은 무엇인가?
• 서비스 등록 및 디스커버리(service registration/discovery): 새로운 마이크로서비스 인스턴스가 배포 될 때 다른 애플리케이션 클라이언트가 발견할 수 있게 만드는 방법은 무엇인가?
• 서비스 모니터링(service monitoring): 마이크로서비스 환경에서 매우 높은 가용성을 요구하기 때
문에 동일 서비스를 여러 인스턴스로 실행히는 것은 일반적이다. 데브옵스 관점에서 마이크 로서비스 인스턴스를 모니터링하고 마이크로서비스 고장을 회피하는 라우텅과 비정상 서비 스 인스턴스를 제거하•지 확인해야 한다.
2.4.1 서비스어셈블리:마이크로서비스의패키징과배포
마이크로서비스 아키텍처의 핵심 개념 중 하나는 애플리케이션의 환경 변화(예를 들어 갑작스런 사용자 요청이 유입되거나 인프라스트럭처의 문제가 발생하는 등) 어1 대
응해 마이크로서비스의 여러 인스턴스를 신속하게 배포할수 있다는 것이다.
mvn clean package && java -jar target/licensing-service-0.0.1-SNAPSHOT.jar
2.4.2 서비스부트스트래핑:마이크로서비스의구성관리
마이크로서비스가 처음 가 동할 때 시작하며 애플리케이션 구성 정보를 로드(load)한다
2.4.3 서비스등록과디스커버리:클라이언트가마이크로서비스와 통신하는 방법
마이크로서비스 소비자 관점에서 마이크로서비스는 위치 투명성을 가져야 한다. 클라우드 기반 환경에서 서버는 일시적(ephemerd)이기 때문이다. ‘일시적’이라는 말은 서비스를 호스팅하는 서버 수명이 기업 데이터센터에서 실행되는 서비스보다 더 짧다는 것을 의미한다. 클라우드 기반 서비 스는 실행될 서버에 완전히 새로운 IP 주소를 할당받고 신속히 시작하고 제거될 수 있다.
모든 서비스에는 고유하고 비영구적인 IP 주소가 할당된다. ‘ 일시적’ 서비스의 단점은 끊임없이 서비스의 시작과 종료를 반복하는 상황에 서 일시적 서비스를 대량으로 수동 또는 직접 관리하면서 장애가 발생할 수 있다는 것이다.
마이크로서비스 인스턴스는 제3 자 에이전트에 스스로 등록해야 하는데 이 등록 과정을 서비스 디 스커버리(service discovery)라고 한다(그림 2 - 6 의 세 번째 단계다). 마이크로서비스 인스턴스를 서비 스 디스커버리 에이전트에 등록할 때 인스턴스의 물리적인 IP 주소 또는 도메인 주소와 애플리케 이션이 서비스 검색에 사용할 논리적인 서비스 이름, 이 두 가지 정보를 에이전트에 전달한다. 어 떤 서비스 디스커버리 에이전트는 상태 확인(ht'akh check)을 하는 데 필요한 URL을 등록하려는 서 비스에 요구하기도 한다.
2.4.4 마이크로서비스의 상태 전달
서비스 디스커버리 에이전트는 클라이언트에 서비스 위치를 안내하는 교통 경찰 역할만 하는 것 은 아니다. 클라우드 기반 마이크로서비스 애플리케이션에서는 종종 어떤 서비스의 많은 인스턴 스가실행될수있고언젠가그서비스인스턴스중하나가고장날것이다. 서비스디스커버리에 이전트는 등록된 각 서비스 상태를 모니터링한다. 그리고 클라이언트가 고장 난 서비스를 호출하 지 않도록 자신의 라우팅 테이블에서 문제가 된 서비스 인스턴스를 제거한다.
마이크로서비스가 실행되면 서비스 디스커버리 에이전트는 해당 서비스가 가용한지 확인하기 위 해 상태 확인 인터페이스(health check interface)를 계속 모니터링하고 핑(ping)한다. 그림 2 - 6 의 네 번 째 단계로 그림 2 - 1 0 에서 자세히 보여 준다.
일관된 상태 확인 인터페이스를 구축하면 여러 클라우드 기반 모니터링 도구를 시용해 문제를 감 지하고 적절히 대응할수 있다.
서비스 디스커버리 에이전트가 어떤 서비스 인스턴스에 문제를 발견하면 망가진 인스턴스를 정지 시키거나 새로운 서비스를 추가하는 등 조치를 취할 수 있다.
REST 기반마이크로서비스환경에서상태확인인터페이스를만드는가장단순한방법은JSON 페이로드와HTTP 상태코드를반환하는HTTP 엔드포인트를노출하는것이다. 스프링부트가 사용되지 않는 마이크로서비스에서 서비스 상태를 제공할 엔드포인트를 작성하는 일은 대개 개발 자 몫이다.
2.6 요약
• 마이크로서비스는 강력한 아키텍처 패러다임이지만 혜택과 장단점이 있다. 모든 애플리케 이션이 마이크로서비스 애플리케이션일 필요는 없다.
• 아키텍트 관점에서 마이크로서비스는 작고, 자체 완비형이며 분산된 것이다. 마이크로서비 스는 좁은 범위와 소규모 데이터를 관리한다.
• 개발자관점에서REST 설계방식과서비스의데이터송수신을위한JSON을사용해마이 크로서비스를 구축한다.
• 데브옵스 관점에서 마이크로서비스를 패키징, 배포,모니터링하는 방법은 매우 중요하다.
• 스프링부트를사용하면서비스를하나의JAR 실행파일로전달할수있다.JAR 파일에내
장된 톰켓 서버가 서비스를 호스팅한다.
• 스프링 부트 프레임워크에 포함된 스프링 액추에이터는 서비스 런타임 정보와 함께 서비스
의 운영 상태 정보도 제공한다.
Note. Twelve-Factor 마이크로서비스 서비스 애플리케이션 구축
이 책을 향한 필자의 큰 바람 중 하나는 여러분이 성공적인 마이크로서비스 아키텍처를 위해 강력한 애플리케이션 개 발과 데브옵스 실천(practice)이 필요함을 깨닫는 것이다. 이러한 실천의 간결한 요약 중 하나가 허로쿠의 Twelveᅳ Factor 애플리케이션 선언(Heroku’s Twelve-Factor Application manifesto, https://12factor.net/)이다. 이 문서는 항상 기억해야 할 12개의 모범 지침을 제공한다. 책을 읽으면서 이러한 실천 사항이 예제에 녹아 있는 것을 알 수 있다.
• 코드베이스(codebase): 모든 애플리케이션 코드와 서버 프로비저닝(provisioning) 정보는 버전 관리(version control)되어야 한다. 각 口ᅡ이크로서비스는 소스 제어 시스템 안에 독립적인 코드 저장소를 가져야 한다.
• 의존성(dependencies): 애플리케이션이 사용하는 의존성을 메이븐(자바) 같은 빌드 도구를 이용해 명시적으로 선언해야 한다. 제3자(3rd party)의 JAR 의존성은 특정 버전 번호를 붙여 명시해 선언해야 한다. 따라서 동일 버전 의 라이브러리를 人f용해 항상 마이크로서비스를 빌드할 수 있다.
• 구성(config): 애플리케이션 구성(특히 환경별 구성)을 코드와 독립적으로 저장하자. 애플리케이션 구성은 절대로 소스 코드와 동일한 저장소에 있으면 안 된다.
• 백엔드 서비스(backing services):마이크로서비스는 대개 네트워크를 거쳐 데이터베이스나 메시징 서비스와 통 신한다. 그렇다면 언제든 데이터베이스 구현을 자체 관리형 서비스에서 외부업체 서비스로 교체할 수 있어야 한다. 10장에서 로컬에서 관리되는 Postgres 데이터베이스를 AWS 데이터베이스로 옮기면서 이를 보여 준다.
• 빌드,릴리스,실행(build, release, run):배포할 애플리케이션의 빌드, 릴리스, 실행 부분을 철저히 분리하라. 코 드가 빌드되면 개발자는 실행 중에 코드를 변경할 수 없다. 모든 변경 사항을 빌드 프로세스로 되돌려 재배포해야 한다. 빌드된 서비스는 불변적이므로(immutable) 변경할 수 없다.
• 프로세스(processes): 마이크로서비스는 항상 무상태(stateless) 방식을 사용해야 한다. 서비스 인스턴스 손실에 의해 데이터가 손실될 것이라는 우려 없이 언제든 서비스를 강제 종료하거나 교체할 수 있다.
• 포트 바인딩(port binding):마이크로서비스는 서비스용 런타임 엔진을 포함한(실행 파일에 패키징된 서비스를 포 함한) 완전히 자체 완비형이다. 별도의 웹 또는 애플리케이션 서버 없이도 서비스는 실행되어야 한다. 서비스는 명 령행에서 단독으로 시작하고 노출한 HTTP 포트를 통해 즉시 액세스할 수 있어야 한다.
• 동시성(concurrency): 확장해야 한다면 단일 서비스 안에서 스레드 모델에 의존하지 마라. 그 대신 더 많은 마이 크로서비스를 시작하고 수평 확장하라. 마이크로서비스 안에서 스레드 人I용을 배제하지는 않지만 확장을 위한 유일 한 메커니즘으로 믿지 말라. 수직 대신 수평 확장하라.
• 폐기 가능(disposability): 마이크로서비스는 폐기 가능하므로 요구에 따라 시작 및 중지할 수 있다. 시작 시간은 최소화하고 운영 체제에서 강제 종료 신호(kill signal雇 받으면 프로세스는 적절히 종료(gracefully shut down) 해야 한다.
• 개발 및 운영 환경 일치(dev/prod parity):서비스가 실행되는 모든 환경(개발자의 데스크톱 환경도 포함) 人삐의 차이를 최소화하라. 개발자는 서비스 개발을 위해 실제 서비스가 실행되는 동일한 인프라스트럭처를 로컬에 사용해 야 한다. 이는 환경 간 서비스 배포가 수 주가 아닌 수 시간 안에 이루어져야 한다는 것을 의미한다. 코드가 커밋되 자마자 테스트되고 가능한 신속하게 개발 환경에서 운영 환경으로 전파되어야 한다.
• 로그(logs): 로그는 이벤트 스트림이다. 로그가 기록될 때 스플렁크(Splunk, http://splunk.com)나 Fluentd (http://fluentd.org) 같은 도구로 로그가 스트리밍되어야 한다. 이들 도구는 로그를 수집해 중앙에 기록한다. 마이 크로서비스는 이러한 로깅 동작 방식에 신경 쓰지 않아야 하며, 개발자는 표준 출력(stdout)으로 출력된 로그를 시 각적으로 확인할 수 있어야 한다.
• 관리 프로세스(Admin processes):개발자는 종종 담당 서비스에 대해 데이터 마이그레이션이나 변환처럼 관리 작업을 수행해야 한다. 이러한 작업은 임의로 수행되면 안 되고 소스 코드 저장소에 유지 및 관리되는 스크립트에 의해 수행되어야 한다. 이 스크립트는 실행될 각 환경에 반복적으로 수행 가능하고 환경을 위해 변경되지 않아야 한 다. 즉, 각 환경에 맞추어 스크립트를 수정하지 않는다.
'프로그래밍 > 스프링' 카테고리의 다른 글
| [스프링 인 액션] 3. JDBC와 JPA (0) | 2024.03.02 |
|---|---|
| [스프링 인 액션] 0. 이 책을 다시 읽는 이유 (0) | 2024.02.27 |
| [스프링 마이크로서비스 코딩 공작소] 1. 스프링, 클라우드와 만나다 (3) | 2023.08.21 |
| [스프링 마이크로서비스 코딩 공작소] 0. 개요 (0) | 2023.08.20 |
| 2. 서블릿 - 1)서블릿 생명주기, 초기화 (0) | 2018.11.18 |