[NoSQL: 빅 데이터 세상으로 떠나는 간결한 안내서] 2장. 집합적 데이터 모델
데이터 모델 : 데이터를 인식하고 조작하는 데 사용되는 모델
지난 20여 년간 가장 지배적인 데이터 모델은 관계형 데이터 모델
각 테이블은 행을 가지며, 각 행은 관심을 가지는 어떤 개체(entity)를 표현.
이 개체는 여러 개의 칼럼으로 기술, 각 칼럼은 하나의 값을 가질 수 있다.
칼럼은 같은 테이블이나 다른 테이블에 있는 행을 참조할 수 있는데, 이를 통해 개체 간 관계가 설정된다.
NoSQL을 사용할 때 가장 명확한 변화는 관계형 모델로부터 멀어진다.
NoSQL 솔루션은 각각 다른 모델을 사용한다.
- Key-Value(키-값)
- 문서
- 칼럼 패밀리
- 그래프
그래프를 제외하고는 집합 지향(aggregate orientation)이라는 특징을 공유한다.
요약
- 세 가지 형태의 집합 지향 데이터 모델에 대한 개요 설명
- 세 형태 모두 집합이란 개념을 공유하고, 집합은 검색할 수 있도록 키로 색인되어 있다.
- 한 집합으로 구성된 데이터는 모두 한 노드에 저장됨을 데이터베이스가 보장한다.
- 집합은 업데이트에 대해 원자적 단위로 동작해, 제한적이지만 유용한 정도의 트랜잭션 제어를 제공한다.
- 집합을 사용하면 클러스터에서 데이터 저장소를 관리하기가 쉬워짐
- 집합-지향 데이터베이스는 모든 데이터 상호작용이 같은 집합으로 이루어질때 가장 좋음
- 상호작용에 여러 가지 다른 형태로 조직된 데이터가 사용된다면 집합 무지 데이터베이스가 낫다.
- 집합의 개념에는 약간의 차이가 있다.
- 키-값 데이터 모델 : 불투명하여 정해져있지 않음. 집합을 키로만 찾을 수 있음
집합의 일부를 질의하거나 꺼내올 수 없음
- 문서 모델 : 투명하고 데이터 타입 강제 가능. 집합의 일부로 쿼리하고 일부만 꺼내올 수 있음.
스키마가 없어서 집합의 일부를 저장하거나 꺼내올 때 문서 구조로 최적화 할 수 있는게 없음.
- 칼럼-패밀리 모델 : 집합을 칼럼 패밀리로 나눔. 칼럼 패밀리를 행 집합 내 단위로만 다루게 함
집합에 약간의 구조를 강제하지만, 이 구조 정보를 이용해 접근성을 향상 시킬 수 있음
2.1 집합
관계형 모델에서는 저장하고자 하는 정보를 튜플(행)로 나눈다. 이는 제한적이다.
집합 지향은 다른 접근법을 취한다.
튜플의 집합보다 더 복잡한 구조(리스트나 중첩 레코드를 허용하는 복잡한 레코드)를 다룰 수 있다.
키-값, 문서, 칼럼-패밀리 모두 복잡한 레코드를 사용하는데, 이 책에서는 '집합(aggregate)'이란 용어를 사용한다.
집합에 대해 더 알아보자
집합은 도메인 주도 개발에서 나온 용어다. 도메인 주도 개발에서 집합은 단위로 다루고 싶은 관련된 객체의 무리를 뜻한다. 특히, 집합은 데이터 조작과 일관성 관리의 단위가 된다. 보통은 원자적 연산으로 집합을 업데이트하고 데이터 저장소와도 집합 단위로 통신한다. 이 정의는 키-값, 문서, 칼럼-패밀리 데이터베이스가 동작하는 방식과 잘 맞는다. 집합응ㄴ 복제(리플리케이션)나 샤딩에서도 자연스러운 단위가 되므로, 데이터베이스가 클러스터에서 데이터를 처리하는 것도 쉬워진다. 또 애플리케이션에서는 데이터를 집합 구조로 조작하는 경우가 많으므로, 프로그래머가 작업하기에도 집합 구조가 더 쉽다.
2.1.1 관계와 집합의 예
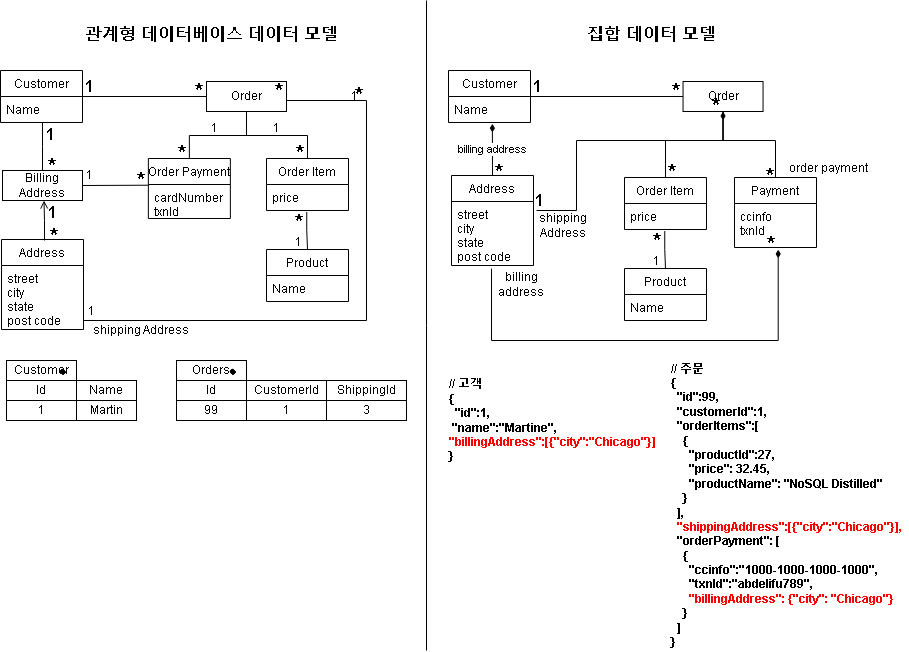
두 가지 주요 집합 : 고객과 주문
데이터가 집합 구조에 어떻게 맞아 들어가는지 보이기 위해 검은색 마름모 기호 사용
집합데이터 모델에서는 논리적으로 하나인 주소가 세 번이나 나온다.
배송지 주소나 청구지 주소가 바뀌지 않는 도메인에서는 이 모델이 잘 맞는다.
고객과 주문 사이의 연결은 어느 집합에도 포함되어 있지 않다.
이는 두 집합 사이의 관계다.

집합의 경계를 다르게 그려, 고객의 모든 주문을 고객 집합에 집어넣을수도 있다.
이에 대한 해답은 없으며, 집합의 경계는 데이터를 조작하는 방식에 따라 달라진다.
고객 데이터에 접근할 때 그 고객의 모든 주문 정보도 한꺼번에 접근하는 경우가 많다면 단일 집합이 좋을 것이다.
그러나 한 번에 한 주문에 집중하는 경우가 대부분이라면 각각을 별도의 집합으로 분리하는 것이 좋다.
2.1.2 집합 지향의 결과
관계형 데이터베이스는 데이터 모델에 집합 개념이 없어 집합 무지(aggregate ignorant)라고 부른다ㅣ
NoSQL 세계에서는 그래프 데이터베이스 또한 집합 무지다.
집합의 경계를 제대로 그리는 것은 어려운 일이며, 똑같은 데이터가 여러 가지 다른 맥락에서 사용되는 경우는 특히 그렇다.
고객이 주문할 때나 주문을 검토할 때, 판매자가 주문을 처리할 때 주문은 좋은 집합이 된다.
그러나 판매자가 지난 몇 달간의 제품 판매 상황을 분석 할 때, 주문 집합은 문제가 된다.
제품 판매 내역을 얻으려고 데이터베이스의 모든 집합을 헤집고 다녀야 한다.
따라서 집합 구조는 도움이 될 때도 있고, 방해가 될 때도 있다.
다양한 데이터 조작 방법이 필요한 경우라면 집합 무지 모델이 더 좋은 선택이다.
집합 지향이 중요한 이유는 클러스터에서 동작하기가 좋기 때문이다.
집합은 트랜잭션에도 중요한 영향을 미친다.
관계형 데이터베이스에서는 단일 트랜잭션 안에서 어떤 테이블의 어떤 행이든 조합해 조작할 수 있다.
이런 트랜잭션을 ACID 트랜잭션이라 부른다.
ACID는 억지로 꾸민 약어다. 실제로 주요한 것은 원자성이다.
NoSQL 데이터베이스는 ACID 트랜잭션을 지원하지 않아서 데이터 일관성을 희생하는 것이라고 흔히 말한다.
보통 집합 지향 데이터베이스는 ACID 트랜잭션을 지원하지 않는다.
대신, 한 번에 한 집합에 대한 원자적 조작은 지원한다.
즉 집합 여러 개를 원자적 방법으로 조작해야 한다면, 이를 애플리케이션 코드에서 직접 관리해야 한다는 뜻이다.
2.2 키-값 모델과 문서 데이터 모델
키-값과 문서는 강력하게 집합 지향적이다.
이 두 형태는 모두 많은 집합으로 구성되어 있고 각 집합은 데이터를 얻는데 사용하는 키나 아이디를 가지고 있따.
- 차이점
키-값 : 집합 구조가 불투명함. 대부분 의미 없는 바이너리 데이터. 무엇이든 저장 가능
문서 : 집합 구조를 볼 수 있음. 집합에 허용되는 구조와 타입을 정의해 제한
실제로는 키-값과 문서의 구분이 조금 모호해졌다.
문서에 키-값처럼 검색하려고 ID필드를 넣는다.
2.3 칼럼 패밀리 저장소
대표적으로 구글의 빅 테이블
빅 테이블은 HBase, Cassandra에 영향을 줌
쓰기는 거의 없지만 많은 행에 대해 칼럼 몇 개만 한꺼번에 읽어야 하는 경우, 모든 행에 대한 칼럼 그룹을 저장 단위로 사용하는 편이 낫다. => 칼럼 저장소
사실 테이블 구조보다는 두 단계로 된 맵(혹은 집합)으로 생각하는 편이 나음
첫 번째 키는 보통 행 ID라 하는데, 관심 집합을 찾는데 사용한다.
칼럼 패밀리 구조는 행 집합 자체가 좀 더 구체적인 값의 맵으로 되어 있다.
두 번째 단계의 값을 칼럼으로 부르는 것이다.
행 전체에 접근하는 것뿐 아니라, 특정 칼럼만 고를 수도 있다.
따라서 특정 고객의 이름을 get('1234', 'name') 같은 식으로 얻을 수 있다.
row key : [1234] -> profile (칼럼 패밀리)
[ name, "martin" ]
[ billingAddress, "..."]
[ payment, "..." ]
칼럼-패밀리 데이터베이스는 칼럼을 칼럼 패밀리로 구조화한다.
= 특정 칼럼 패밀리에 대한 데이터는 보통 함께 접근되면 유리